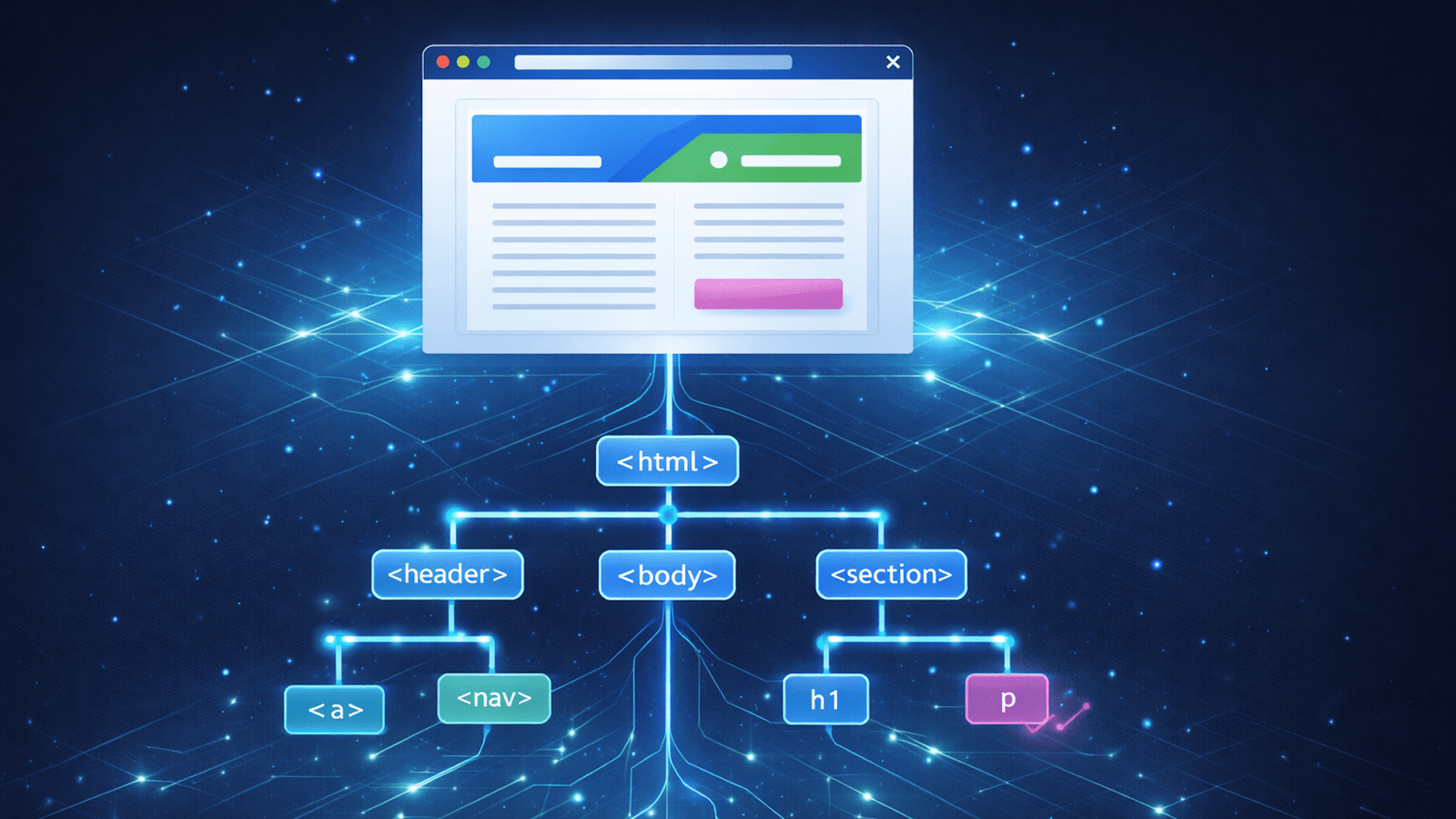
These tokens are then converted into distinct “nodes,” which serve as the building blocks of the page. The browser links these nodes together in a parent-child hierarchy to form the tree structure.
You can visualize the process like this:

It’s important to know that the browser simultaneously creates a tree-like structure for CSS, known as the CSS Object Model (CSSOM), which allows JavaScript to read and modify CSS dynamically. However, for SEO, the CSSOM matters far less than the DOM.
JavaScript execution
JavaScript often executes while the tree is still being built. If the browser encounters a
During this execution, scripts can modify the DOM by injecting new content, removing nodes, or changing links. This is why the HTML you see in View Source often looks different from what you see in the Elements panel.
Here’s an example of what I mean. Each time I click the button below, it adds a new paragraph element to the DOM, updating what the user sees.

Your HTML is the starting point, a blueprint, if you will, but the DOM is what the browser builds from that blueprint.
Once the DOM is created, it can change dynamically without ever touching the underlying HTML file.
Dig deeper: JavaScript SEO: How to make dynamic content crawlable
Get the newsletter search marketers rely on.
Why the DOM matters for SEO
Modern search engines, such as Google, render pages using a headless browser (Chromium). This means that they evaluate the DOM rather than just the HTML response.
When Googlebot crawls a page, it first parses the HTML, then uses the Web Rendering Service to execute JavaScript and take a DOM snapshot for indexing.
The process looks like this:

However, there are important limitations to understand and keep in mind for your website:
- Googlebot doesn’t interact like a human. While it builds the DOM, it doesn’t click, type, or trigger hover events, so content that appears only after user interaction may not be seen.
- Other crawlers may not render JavaScript at all. Unlike Google, some search engines and AI crawlers only process the initial HTML response, making JavaScript-dependent content invisible.
Looking ahead to a world that’s becoming more AI-dependent, AI agents will increasingly need to interact with websites to complete tasks for users, not just crawl for indexing.
These agents will need to navigate your DOM, click elements, fill forms, and extract information to complete their tasks, making a well-structured, accessible DOM even more critical than ever.
Verifying what Google actually sees
The URL inspection tool in Google Search Console shows how Google renders your page’s DOM, also known in SEO terms as the “rendered HTML,” and highlights any issues Googlebot might have encountered.
This tool is crucial because it reveals the version of the page Google indexes, not just what your browser renders. If Google can’t see it, it can’t index it, which could impact your SEO efforts.
In GSC, you can access this by clicking URL inspection, entering a URL, and selecting View Crawled Page.
The panel below, marked in red, displays Googlebot’s version of the rendered HTML.

If you don’t have access to the property, you can also use Google’s Rich Results Test, which lets you do the same thing for any webpage.
Dig deeper: Google Search Console URL Inspection tool: 7 practical SEO use cases
Shadow DOM: An advanced consideration
The shadow DOM is a web standard that allows developers to encapsulate parts of the DOM. Think of it as a separate, isolated DOM tree attached to an element, hidden from the main DOM.
The shadow tree starts with a shadow root, and elements attach to it the same way they do in the light (normal) DOM. It looks like this:

Why does this exist? It’s primarily used to keep styles, scripts, and markup self-contained. Styles defined here cannot bleed out to the rest of the page, and vice versa. For example, a chat widget or feedback form might use shadow DOM to ensure its appearance isn’t affected by the host site’s styles.
I’ve added a shadow DOM to our sample page below to show what it looks like in practice. There’s a new div in the HTML file, and JavaScript then adds a div with text inside it.

When rendering pages, Googlebot flattens both shadow DOM and light DOM and treats shadow DOM the same as other DOM content once rendered.
As you can see below, I put this page’s URL into Google’s Rich Results Test to view the rendered HTML, and you can see the paragraph text is visible.

Technical best practices for DOM optimization
Follow these practices to ensure search engines can crawl, render, and index your content effectively.
Load important content in the DOM by default
Your most important content must be in the DOM and appear without user interaction. This is imperative for proper indexing. Remember, Googlebot renders the initial state of your page but doesn’t click, type, or hover on elements.
Content that is added to the DOM only after these interactions may not be visible to crawlers. One caveat is that accordions and tabs are fine as long as the content already exists in the DOM.
As you can see in the screenshot below, the paragraph text is visible in the Elements panel even when the accordion tab has not been opened or clicked.

Use proper tags for links
As we all know, links are fundamental to SEO. Search engines look for standard tags with href attributes to discover new URLs. To ensure they discover your links, ensure the DOM shows real links. Otherwise, you risk crawl dead ends.
You should also avoid using JavaScript click handlers (e.g., ) for navigation, as crawlers generally won’t execute them.
Like this:

Use semantic HTML structure
Use heading tags (,
,
etc.) in logical hierarchy and wrap content in semantic elements like
, and
that correctly describe the site’s content. Search engines use this structure to understand pages.
A common issue with page builders is making DOMs full of nested
Ensure to maintain the same semantic standards you’d follow in static HTML.
Here’s a snippet of semantic HTML as an example:
Here’s an example of “div soup” HTML that’s non-semantic and harder for search engines and assistive technologies to understand.
Optimize DOM size to improve performance
Keep the DOM lean, ideally under ~ 1,500 nodes, and avoid excessive nesting. Remove unnecessary wrapper elements to reduce style recalculation, layout, and paint costs.
Here’s an example from web.dev of excessive nesting and an unnecessarily deep DOM:
While DOM size is not a Core Web Vital itself, excessive and deeply nested DOMs can indirectly impact performance, especially on lower-end devices.
To mitigate these impacts:
- Limit layout-affecting DOM changes after initial render to reduce Cumulative Layout Shift (CLS).
- Render critical above-the-fold content early to improve Largest Contentful Paint (LCP).
- Minimize JavaScript execution and long tasks to improve Interaction to Next Paint (INP).
See the complete picture of your search visibility.
Track, optimize, and win in Google and AI search from one platform.
Start Free Trial
Get started with

The DOM’s importance will only continue growing
A workable understanding of the DOM can help you not only diagnose SEO issues, but also effectively communicate with developers and others on your team.
We know that the DOM impacts Core Web Vitals, crawlability, and indexing. As AI agents increasingly interact with websites, DOM optimization becomes more critical. It’s important to master these fundamentals now to stay ahead of evolving search and AI technologies.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. Search Engine Land is owned by Semrush. Contributor was not asked to make any direct or indirect mentions of Semrush. The opinions they express are their own.