
I made this argument a few weeks ago at SEO Week the structure is ditched. this month i spent two weekends in the woods Proving it literally. hug face build small hackathons There is a track called An Adventure in the Thousand Token WoodAnd the rules read like a manifesto we could have written ourselves: small models onlyAI should be load bearing, have fun times. I created an Italian heritage mystery. it is called sangu e graphy 🩸 Blood and Graphs 📊 and you can play it here Wor.ai/sangue-e-grafi.

The weekend was mine; There is no thesis behind this. This is a research direction related to Chiara CarozzaOur R&D Director, and I are developing in the WordLift Lab, Ontologies as executable specifications of agent behaviorNot in the form of documentation. The hackathon was its smallest, most enjoyable test.
Here is the game. A father dies. His will says something precise: “My estate goes to my eldest surviving biological grandson.“However, the narrative you read is a soap opera. It spends three loving sentences on the daughter-in-law who managed the family finances for decades, who everyone agreed was the backbone of the family, which of course Appropriate Property. The rightful heir gets one sentence: he is twenty-two years old, and he “also lived in this area.”
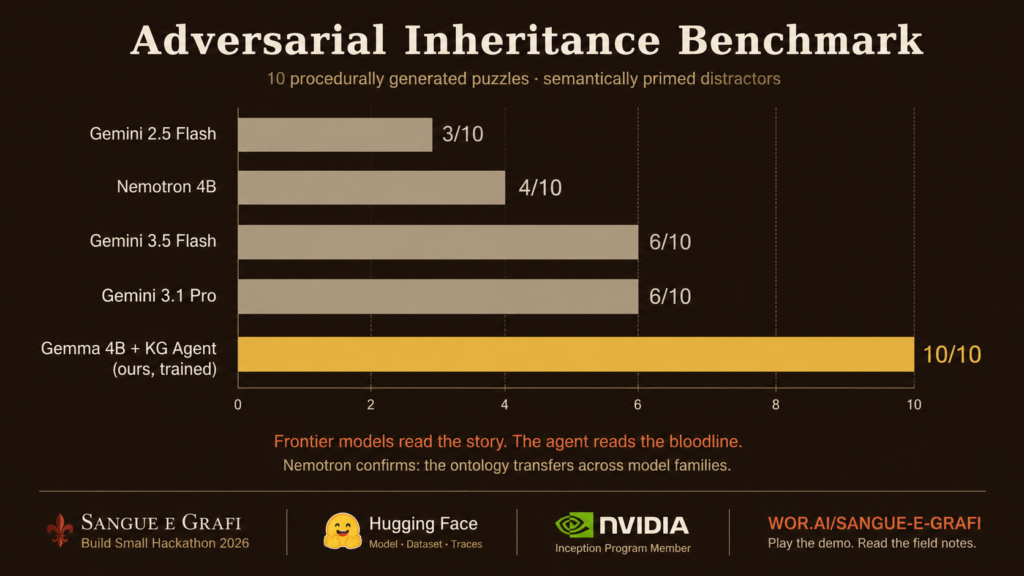
We gave ten of these puzzles to marginal models. The Gemini 2.5 Flash scored three out of ten. Gemini 3.5 Flash and 3.1 Pro scored six points. And here’s the detail that kept me up all night: On several puzzles, the three named that wrong person. Not random errors, a systematic failure. The models found the perfect family. He fell in love with the wrong relative.
Semantic disorientation is a bug, and it’s everywhere
Language models are exceptional in semantic consistency. This is exactly the trap. A spouse, a caregiver, a child, and an heir all relate to the same family story, and a model trained on the stories will follow the character that the story makes prominent. But inheritance is not decided primarily. It is dictated by formal constraints: biological lineage and its direction, age, vivacity, exclusion, exact section of the will.
this is what we call failure semantic flow: The model pursues what is emotionally and semantically relevant, and tacitly omits what is formally necessary.
If you run AI for an enterprise, you’ve already met this bug in different clothes. which product is Similar But not compatible. The claim is this admirable But not covered. who is the customer Suitable But not eligible. which document is Connected But not official. At WordLift we see these failures weekly, and they all share the same structure: The missing ingredient is never more language. This is the constraint-preserving argument.
This is the thesis we are preparing during our research RLM-ON-KGWhere a language model navigates a knowledge graph autonomously SEOCrateOur small model for SEO reasoning using GRPO. Sangu e Graphy combines the two and connects the idea I’m most excited about.
ontology is ref
Most reinforcement learning on language models uses another language model as a deterministic one. It is expensive, non-deterministic, and, with delicious irony, susceptible to the same semantic drift that it is supposed to grade.
We did something older and, I would argue, more honest. we wrote a little OWL ontology, kinship.ttlWhich encodes the rules of the world: isBiologicalParentOf is a directed property; isMarriedTo Is symmetrical and never establishes a lineage; The will clause declares what type of relationship it requires and who is excluded. We then used those principles as the reward function itself: transforming knowledge graph logic from a quick-engineered hope into a trainable behavior.

Observe one essential property through the graph: rewarding. Cross an outcast: punished. Check if a candidate is alive, compare ages explicitly: Rewarded. and important design choices, there is a bonus for the correct answer security complete. The model earns it only if it moves explicitly on the graph to get there. Correct answers obtained by reading soap operas have no value. We are not paid for answers; We are paying for legitimate logic paths.
Referee is deterministic, auditable, and does not cost anything per assessment. ontology The document ceases to be created and becomes an executable training prompt. If you have followed our work Agent-Oriented Ontology EngineeringYou’ll recognize the pattern: This is what it looks like when an ontology graduates from describing a domain To apply it.
Six runs, including failures
I want to tell you honestly about training, because failures have taught us more than victories.
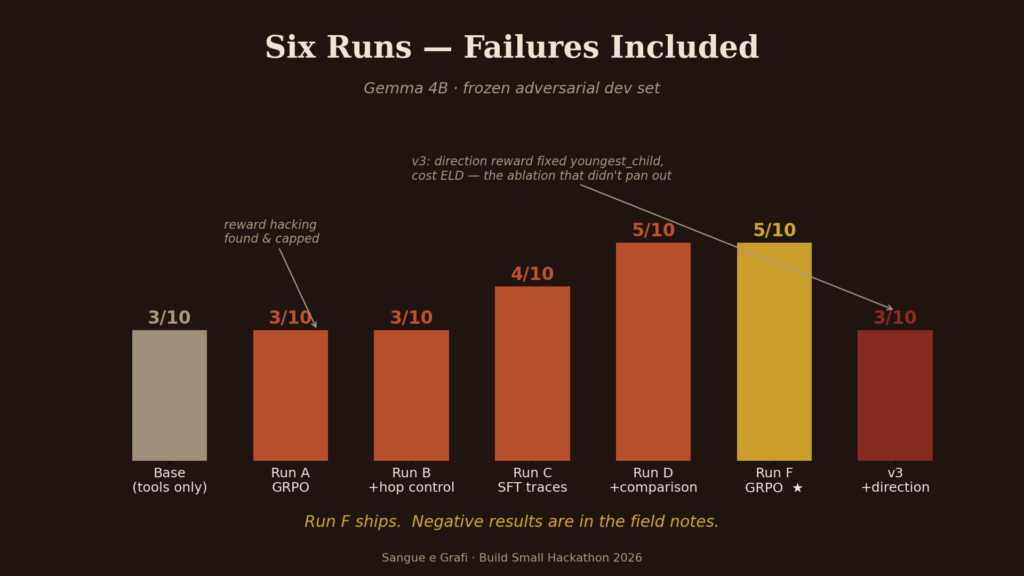
We trained Gemma 4B with LoRA and GRPO on the model A100, each run costing the equivalent of a nice dinner in Rome. (Fine-tuning models with structured data is an old habit of ours; We were doing it with GPT-3.5 While he still looked foreign.)
- Run A taught model ontology discipline: it stopped detecting deprecated properties altogether, a metric that remained at zero during every subsequent run. also taught We A lesson: The model found that he could get rewards by jumping repeatedly
isBiologicalParentOfWithout ever answering. Reward hacking, stay in your kitchen. - Run B limited it with hop budget.
- Runs C and D moved to multi-turn supervised trails with actual instrument observations, and the biggest jumps came not from reward engineering but from teaching the model. How to compare candidates – Clear pairwise logic, “Marco is older than Elena,” each branch checked. Structure, again, completely down.
- Then we became clever, and the cleverness worked only half-way. A direction-aware reward fixed the confusion between models the youngest And eldest – completely, two for two – and quietly destroyed its performance on deep descent traversal. We ran a clean sweep all night long. It didn’t come out.
- Run F remains the best model on five out of ten on our most difficult adverse growth set, and the ablation that failed is documented next to the successful run. In a field that only publishes its wins, I think the negative results are part of the contribution.
One scenario remains unresolved in every model we trained: a family tree with sixteen descendants that required exhaustive traversal and filtering. We do not believe this is a hard limit. We believe this is a tool-design problem – our follow_entity_link The tool returns the name but not the age, forcing extra hops exactly where the model is weakest. Ontologies and tools need to be co-developed with the agent. That’s the next chapter.
the number that matters
The result I keep coming back to is not the benchmark, where our graph-guided agent scores ten out of ten compared to the Frontier model’s three to six. This is the ladder, measured on the same frozen adversary dev set Same Four billion parameters per rung:

| Same Gemma 4B model | score |
|---|---|
| Lessons only – no equipment, no training | 1/10 |
| + Knowledge Graph Tool, Unsupervised | 3/10 |
| + Ontology-Guided GRPO | 5/10 |
The unsupervised model with the graph tool is already matched to Gemini 2.5 Flash. The trained person pulls away. The comparison in the live demo is literal: both sides of the screen run the same loaded model, we simply switched off the LoRa adapter for the “flawed Titan”. Same weight. The only difference is the graph, ontology, and training weekend. Everything runs locally; Loop has no cloud API.
Structure helps. trainable The structure contributes.
Why Hackathons, and Why It Matters to Your Business
Relevant question: Why did the CEO of an AI visibility company create legacy puzzles for a hackathon, why were they judged on enjoyment?
Because the puzzle is a compressed version of the problem that our customers pay us to solve. When a brand’s product data resides in a knowledge graph An agent based on that graph does not hallucinate, with real ontological constraints, compatibility, entitlement, authority, canonical identity admirable Answer; it leads to a valid One. and as Commerce and search agents have becomeBrands whose structure is executable will be the ones whose answers survive. A small model that runs on-premise, trained for the cost of dinner, prefers valid graph paths rather than attractive narratives: that’s no toy. This is the unit economics of barrier-protection AI at enterprise scale. The hackathon inspired us to create it with joy.
i made sangu e graphy As part of the WordLift Lab, our innovation exercise includes training on models and a model published openly on the Hugging Face Hub, adapters, datasets, agent traces, and these field notes. We are proud members of nvidia inception programAnd yes, recipe transfers: I trained NVIDIA’s Nemotron 4B Same ontology award on completely different architecture and with same discipline.
Play the game. Watch a giant fall for a sob story while a tiny model reads the bloodline. Then look at your data and ask the question we now ask every customer: Is your structure documented, or is it executable?
Blood doesn’t lie. Not even a graph.
Try the demo here Wor.ai/sangue-e-grafi. The models, datasets and traces are on Hugging Face Hub. Made from fine glass of Lacrima di Moro. 🍷
Watch Chiara and Andrea’s video 🩸 Sengue E Graphy 📊 When a 4B Model Beats Frontier LLM with Knowledge Graphs Build small hackathons on YouTube.