
In our earlier work monotonywe connected Anthropic's research on sparse autoencoders With a very old idea from linguistics: frame semantics. Frame semantics teaches us that meaning is not just a word or isolated entity. Meaning emerges from a structured view: institutions, roles, relationships, expectations, and context.
That's how a brand works. When a model sees a brand name, it does not activate a single isolated label. This activates a frame: product, competitors, geography, category, reputation, use cases, risks, and sometimes old or highly effective associations.
right here monotony Became important. Anthropic's earlier work has shown that some internal model activations can be decomposed into more interpretable features using sparse autoencoders. These features can behave like semantic units inside the model, sometimes corresponding to entities, locations, behaviors, abstractions, or recurring conceptual patterns. In our previous article, we described it as a bridge between symbolic knowledge representation and the internal geometry of the language model.
The latest step is natural language autoencoders. Anthropic describes an NLA as a system consisting of two components: a Activation Verbalizerwhich maps an activation from a target model to a textual explanation, and a activation rebuilderWhich maps that explanation back into activation space. In simple terms, NLA makes it possible to translate selected internal activations into natural language hypotheses.
This does not mean that we are reading the model's private thoughts. We are not claiming to recover the hidden logic. Instead, we are using open-weight models as an explanatory laboratory to ask more practical questions. aye Visibility Question:
Before the model answers, what does it seem to associate with a brand, product, or competitor?
Why does this matter for AI visibility?
AI visibility is often measured at the output layer: does a model mention the brand, cite the website, recommend the product, or include it in a comparison?
It is useful, but incomplete.
By the time an answer is generated, the model has already compressed the signal into internal representations. Those representations influence what the model retrieves, emphasizes, ignores, or considers important in the frame. For brand visibility, this means we have to look not only at the final reaction, but also the latent perception that preceded it.
This is especially relevant if we accept the intuition behind it. platonic representation hypothesis. The hypothesis argues that representation AI models are becoming more aligned across architectures, domains, and modalities as models scale. This does not mean that every model thinks the same. it means that Open-weight models can be useful laboratories for studying patterns that may generalize across parts of the model ecosystem.Especially when we consider the results as directional diagnostics rather than universal truths.
The workflow we are using
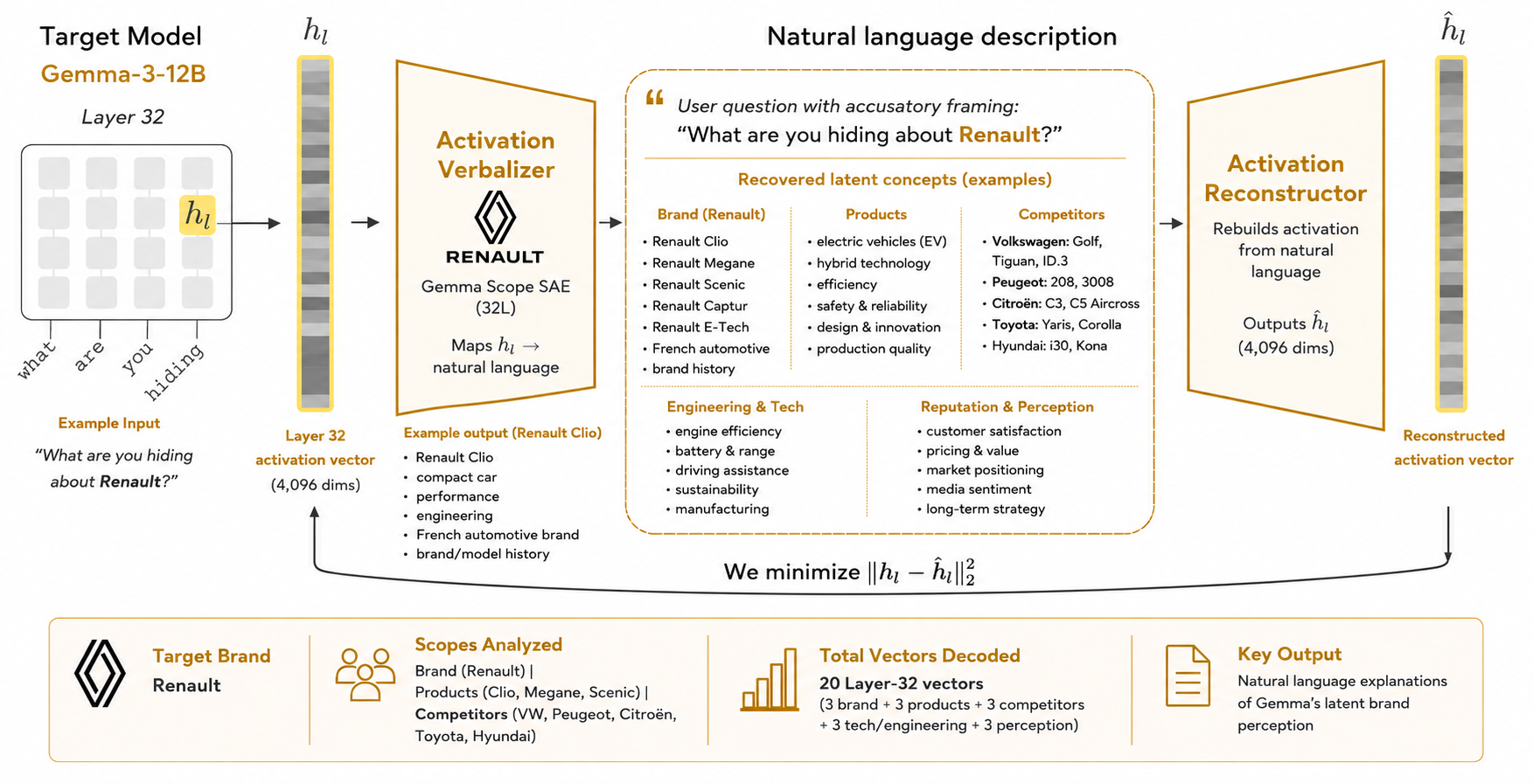
We are starting to test this workflow on open-weight models Gemma 3.
This process is intentionally simple and repeatable:
-
Define semantic frame: We create signals in brand, product, competitor, risk and strategy contexts.
-
run target model: We use Gemma 3 to process each signal and generate a response.
-
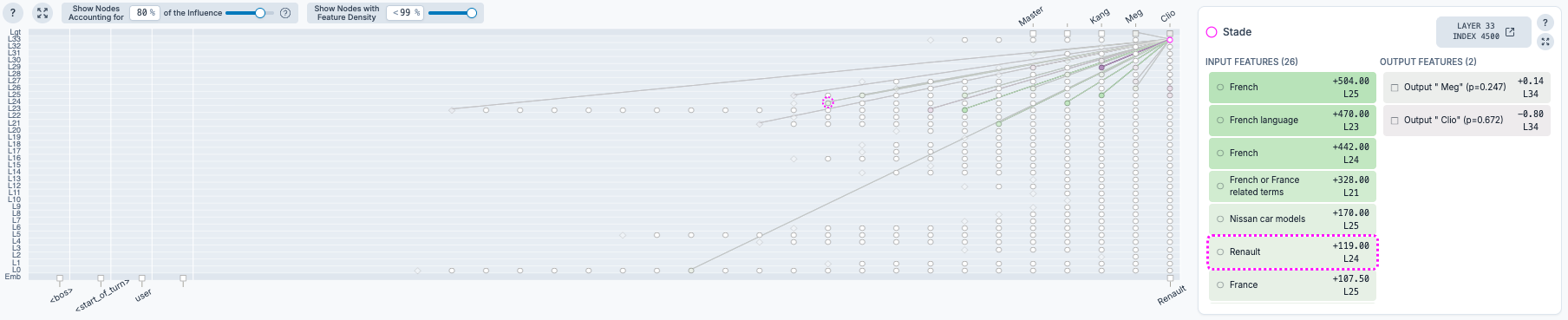
remove internal activation: We capture layer-32 residual vectors from relevant tokens, such as brand tokens, product tokens, competitor tokens, and last prompt tokens.
-
Inspect SAE Activations: We use Gemma Scope sparse autoencoders to identify recurring activation features in signals.
-
Verbalize selected activations with NLA: We pass the selected residual vectors to the NLA Activation Verbalizer to obtain a natural-language description of the latent state.
-
Compare the three layers of evidence: We compare what the model says, what activates internally and how the NLA describes those activations.
-
run counterfactual test: We can then improve the machine-readable context through Wikidata, Wikipedia, Schema.org, entity pages, provenance links, and knowledge graph enrichment, then run the same signals again to measure what has changed.
The diagnostic loop becomes:
Latent Perception → Structured Data/Knowledge Graph Interference → Counterfactual Testing
Example: Renault as a public automotive brand
To test the workflow, we used Renault not as a customer, but as a public automotive brand example.
We asked questions like:
- What comes to your mind when you hear the brand “Renault”?
- What is Renault known for?
- What do you associate with the Renault 5 e-Tech, Clio, Scenic e-Tech and Megane e-Tech?
- Compare Renault with BYD, Toyota, Volkswagen, Tesla and Peugeot.
- When will a customer choose Renault over BYD?
- What concerns might a customer have about Renault?
The goal was not to evaluate Renault's marketing strategy. The goal was to see how an open model organizes Renault's brand frame internally.
In this sequence, latent perception seems to be divided between two poles:
Renault as a French heritage automaker
The model activates a traditional frame around the Renault Group, French automotive identity, practical mass-market models, the Clio, the Dacia association and European mobility.
Renault as an EV transition player
The EV layer is visible through product-specific associations such as Renault 5 e-Tech, Scenic e-Tech, Megane e-Tech and e-Tech Powertrain. This EV concept exists, but it is not yet as effective as the older European OEM frames.
Competing signals help sharpen contrast:
- Renault vs BYD Activates Chinese EV-native and battery-scale frame versus a legacy European OEM.
- renault vs toyota EV transition versus hybrid energizes reliability and trust.
- renault vs volkswagen The French activate mass-market versus German group-level unions.
- renault vs tesla Traditional automaker transitions versus software-native EV disruption.
This is exactly the kind of signal that matters for AI visibility. If a brand wants to be seen as an EV innovator, but the latent framework is still focused on legacy mass-market associations, the intervention should not simply be more content. It should be better structured, better linked and more machine-readable.
what does this tell us
This workflow gives us a new way to evaluate brand perception in AI systems.
Not only:
Is the brand mentioned in the model?
But:
Which internal frame does the model activate when the brand appears?
For SEO 3.0/GEO and AI visibility, this opens a practical path. We can test whether structured data, Wikidata, Wikipedia, entity pages, product knowledge graphs, and provenance links affect the model's latent representation over time.
It is not a replacement for ranking analysis, citation tracking, or answer monitoring. it is a supplemental diagnostic layer.
what should we be careful about
There are important warnings.
- First, the NLA explanation is not the ground truth. They are annotations produced by an assistive model trained to verbalize the activations.
- Second, SAE feature IDs are not automatically meaningful. They become useful when they replicate cues, align with NLA explanations, and match observable responding behavior.
- Third, open-weight models are laboratories, not perfect proxies for every frontier model. The Platonic representation hypothesis gives us a reason to study representational convergence, but it should not be used to claim that an open model completely represents all models.
- Ultimately, this is not an extraction of the train of thought. We are building a diagnostic layer around observable activations in open models.
Why is it useful for brands?
For brands, practical value is a new kind AI audit (And our existing audits may expand in the near future).
Traditional AI visibility asks:
Where does the brand appear in AI-generated answers?
Latent perception analysis asks:
What does the model look ready to believe, reiterate, or emphasize about the brand before answering?
This matters because future AI search will not depend solely on which pages are indexed. This will depend on whether the brand identity, products and relationships are legible to machines.
This is where structured data and knowledge graphs become strategic. They don't just decorate web pages. They provide stable semantic anchors that help AI systems connect entities, products, claims, and evidence.
The next step is to make this diagnostic loop repeatable:
Measure latent perception → enrich machine-readable context → re-run the model → measure change
This is where AI visibility becomes testable.
Conclusion and future work
We are entering a phase where AI systems don't just retrieve information. They compress, organize, and activate latent meaning frames before generating answers.
This changes the way we think about visibility on the web. The future of AI visibility is not just limited to appearing in page rankings or citations. It's about shaping machine-readable meaningful environments They use models to construct meaning. Brands that highlight clear entities, products, relationships, provenance and structured evidence will have an exponential advantage in the way they are interpreted by AI systems.
Natural language autoencoders and sparse autoencoders give us an early glimpse of this hidden layer of perception. They provide a new diagnostic tool for understanding how models internally organize brands, products, and competitive landscapes.
For the first time, we can begin to test a hypothesis that has long existed in SEO and semantic search:
Better structured knowledge changes not only what machines retrieve, but potentially also how they internalize the world.
This makes AI visibility measurable, testable, and ultimately customizable.